CatBoost算法梳理
CatBoost
CatBoost是俄罗斯的搜索巨头Yandex在2017年开源的机器学习库,也是Boosting族算法的一种,同前面介绍过的XGBoost和LightGBM类似,依然是在GBDT算法框架下的一种改进实现,是一种基于对称决策树(oblivious trees)算法的参数少、支持类别型变量和高准确性的GBDT框架,主要说解决的痛点是高效合理地处理类别型特征,这个从它的名字就可以看得出来,CatBoost是由catgorical和boost组成,另外是处理梯度偏差(Gradient bias)以及预测偏移(Prediction shift)问题,提高算法的准确性和泛化能力。
CatBoost主要有以下五个特性:
- 无需调参即可获得较高的模型质量,采用默认参数就可以获得非常好的结果,减少在调参上面花的时间
- 支持类别型变量,无需对非数值型特征进行预处理
- 快速、可扩展的GPU版本,可以用基于GPU的梯度提升算法实现来训练你的模型,支持多卡并行
- 提高准确性,提出一种全新的梯度提升机制来构建模型以减少过拟合
- 快速预测,即便应对延时非常苛刻的任务也能够快速高效部署模型
CatBoost的主要算法原理可以参照以下两篇论文:
Categorical features
所谓类别型变量(Categorical features)是指其值是离散的集合且相互比较并无意义的变量,比如用户的ID、产品ID、颜色等。因此,这些变量无法在二叉决策树当中直接使用。常规的做法是将这些类别变量通过预处理的方式转化成数值型变量再喂给模型,比如用一个或者若干个数值来代表一个类别型特征。
目前广泛用于低势(一个有限集的元素个数是一个自然数)类别特征的处理方法是One-hot encoding:将原来的特征删除,然后对于每一个类别加一个0/1的用来指示是否含有该类别的数值型特征。One-hot encoding可以在数据预处理时完成,也可以在模型训练的时候完成,从训练时间的角度,后一种方法的实现更为高效,CatBoost对于低势类别特征也是采用后一种实现。
显然,在高势特征当中,比如 user ID,这种编码方式会产生大量新的特征,造成维度灾难。一种折中的办法是可以将类别分组成有限个的群体再进行 One-hot encoding。一种常被使用的方法是根据目标变量统计(Target Statistics,以下简称TS)进行分组,目标变量统计用于估算每个类别的目标变量期望值。甚至有人直接用TS作为一个新的数值型变量来代替原来的类别型变量。重要的是,可以通过对TS数值型特征的阈值设置,基于对数损失、基尼系数或者均方差,得到一个对于训练集而言将类别一分为二的所有可能划分当中最优的那个。在LightGBM当中,类别型特征用每一步梯度提升时的梯度统计(Gradient Statistics,以下简称GS)来表示。虽然为建树提供了重要的信息,但是这种方法有以下两个缺点:
- 增加计算时间,因为需要对每一个类别型特征,在迭代的每一步,都需要对GS进行计算;
- 增加存储需求,对于一个类别型变量,需要存储每一次分离每个节点的类别。
为了克服这些缺点,LightGBM以损失部分信息为代价将所有的长尾类别归位一类,作者声称这样处理高势特征时比起 One-hot encoding还是好不少。不过如果采用TS特征,那么对于每个类别只需要计算和存储一个数字。
如此看到,采用TS作为一个新的数值型特征是最有效、信息损失最小的处理类别型特征的方法。TS也被广泛采用,在点击预测任务当中,这个场景当中的类别特征有用户、地区、广告、广告发布者等。接下来我们着重讨论TS,暂时将One-hot encoding和GS放一边。
Target statistics
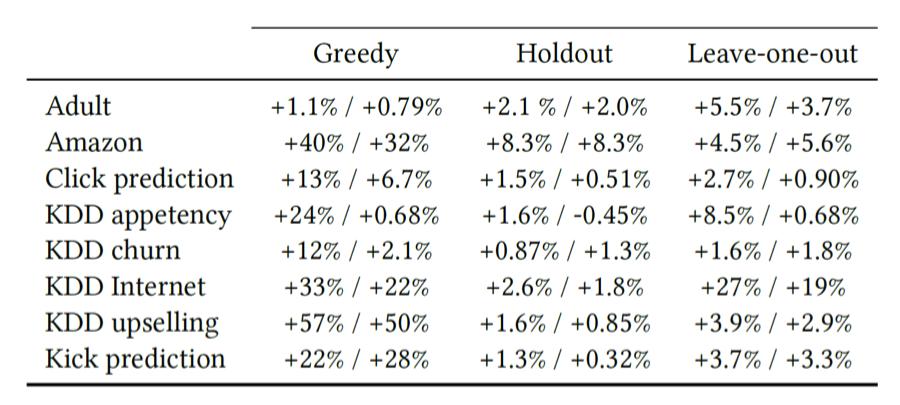
一个有效和高效的处理类别型特征下面是Ordered TS与其它各种TS在不同数据集上面在logloss/zero-one loss上面的效果比较:
特征组合
CatBoost的另外一项重要实现是将不同类别型特征的组合作为新的特征,以获得高阶依赖(high-order dependencies),比如在广告点击预测当中用户ID与广告话题之间的联合信息,又或者在音乐推荐引用当中,用户ID和音乐流派,如果有些用户更喜欢摇滚乐,那么将用户ID和音乐流派分别转换为数字特征时,这种用户内在的喜好信息就会丢失。然而,组合的数量会随着数据集中类别型特征的数量成指数增长,因此在算法中考虑所有组合是不现实的。为当前树构造新的分割点时,CatBoost会采用贪婪的策略考虑组合。对于树的第一次分割,不考虑任何组合。对于下一个分割,CatBoost将当前树的所有组合、类别型特征与数据集中的所有类别型特征相结合,并将新的组合类别型特征动态地转换为数值型特征。CatBoost还通过以下方式生成数值型特征和类别型特征的组合:树中选定的所有分割点都被视为具有两个值的类别型特征,并像类别型特征一样地被进行组合考虑。
Gradient bias
CatBoost,和所有标准梯度提升算法一样,都是通过构建新树来拟合当前模型的梯度。然而,所有经典的提升算法都存在由有偏的点态梯度估计引起的过拟合问题。在每个步骤中使用的梯度都使用当前模型中的相同的数据点来估计,这导致估计梯度在特征空间的任何域中的分布与该域中梯度的真实分布相比发生了偏移,从而导致过拟合。为了解决这个问题,CatBoost对经典的梯度提升算法进行了一些改进,简要介绍如下:
在许多利用GBDT框架的算法(例如,XGBoost、LightGBM)中,构建下一棵树分为两个阶段:选择树结构和在树结构固定后计算叶子节点的值。为了选择最佳的树结构,算法通过枚举不同的分割,用这些分割构建树,对得到的叶子节点中计算值,然后对得到的树计算评分,最后选择最佳的分割。两个阶段叶子节点的值都是被当做梯度或牛顿步长的近似值来计算。在CatBoost中,第二阶段使用传统的GBDT框架执行,第一阶段使用修改后的版本。
既然原来的梯度估计是有偏的,那么能不能改成无偏估计呢?
设
Prediction shift
预测偏移(Prediction shift)是由上一节所讨论的梯度偏差造成的。本节希望用数学语言严格地对预测偏差进行描述和分析。
首先来看下梯度提升的整体迭代过程:
- 对于梯度提升:Ordered boosting
为了克服上一节所描述的预测偏移问题,我们提出了一种新的叫做Ordered boosting的算法。假设用棵树来学习一个模型,为了确保无偏,需要确保模型的训练没有用到样本。由于我们需要对所有训练样本计算无偏的梯度估计,乍看起来对于的训练不能使用任何样本,貌似无法实现的样子,但是事实上可以通过一些技巧来进行克服,具体的算法在前面已经有所描述,而且是作者较新的论文当中的描述,这里不再赘述。本节主要讲讲Ordered boosting的具体实现。
Ordered boosting算法好是好,但是在大部分的实际任务当中都不具备使用价值,因为需要训练个不同的模型,大大增加的内存消耗和时间复杂度。在CatBoost当中,我们实现了一个基于GBDT框架的修改版本。
前面提到过,在传统的GBDT框架当中,构建下一棵树分为两个阶段:选择树结构和在树结构固定后计算叶子节点的值。CatBoost主要在第一阶段进行优化。
First phase
在建树的阶段,CatBoost有两种提升模式,Ordered和Plain。Plain模式是采用内建的ordered TS对类别型特征进行转化后的标准GBDT算法。Ordered则是对Ordered boosting算法的优化。
Ordered boosting mode
一开始,CatBoost对训练集产生个独立的随机序列。序列用来评估定义树结构的分裂,用来计算所得到的树的叶子节点的值。因为,在一个给定的序列当中,对于较短的序列,无论是TS的计算还是基于Ordered boosting的预测都会有较大的方差,所以仅仅用一个序列可能引起最终模型的方差,这里我们会有多个序列进行学习。
CatBoost采用对称树作为基学习器,对称意味着在树的同一层,其分裂标准都是相同的。对称树具有平衡、不易过拟合并能够大大减少测试时间的特点。建树的具体算法如下伪码描述。

Plain boosting mode
Plain boosting模式的算法与标准GBDT流程类似,但是如果出现了类别型特征,它会基于得到的TS维持个支持模型。
Second phase
当所有的树结构确定以后,最终模型的叶子节点值的计算与标准梯度提升过程类似。第个样本与叶子进行匹配,我们用来计算这里的TS。当最终模型在测试期间应用于新的样本,我们采用整个训练集来计算TS。
GPU加速
就GPU内存使用而言,CatBoost至少与LightGBM一样有效,CatBoost的GPU实现可支持多个GPU,分布式树学习可以通过样本或特征进行并行化。
sklearn参数
sklearn本身的文档当中并没有CatBoost的描述,CatBoost python-reference_parameters-list上面看到主要参数如下:
iterations: 迭代次数, 解决机器学习问题能够构建的最大树的数目,default=1000learning_rate: 学习率,default=0.03depth: 树的深度,default=6l2_leaf_reg: 正则化数,default=3.0model_size_reg:模型大小正则化系数,数值越到,模型越小,仅在有类别型变量的时候起作用,取值范围从0到,GPU计算时不可用, default=Nonersm: =None,loss_function: 损失函数,字符串 (分类任务,default=Logloss,回归任务,default=RMSE)border_count: 数值型变量的分箱个数- CPU:1~65535的整数,default=254
- GPU:1~255的整数,default=128
feature_border_type: 数值型变量分箱个数的初始量化模式,default=GreedyLogSum- Median
- Uniform
- UniformAndQuantiles
- MaxLogSum
- MinEntropy
- GreedyLogSum
per_float_feature_quantization: 指定特定特征的分箱个数,default=None,input_borders=None,output_borders=None,fold_permutation_block: 对数据集进行随机排列之前分组的block大小,default=1od_pval: 过拟合检测阈值,数值越大,越早检测到过拟合,default=0od_wait: 达成优化目标以后继续迭代的次数,default=20od_type: 过拟合检测类型,default=IncToDec- IncToDec
- Iter
nan_mode: 缺失值的预处理方法,字符串类型,default=MinForbidden: 不支持缺失值Min: 缺失值赋值为最小值Max: 缺失值赋值为最大值
counter_calc_method: 计算Counter CTR类型的方法,default=Noneleaf_estimation_iterations: 计算叶子节点值时候的迭代次数,default=None,leaf_estimation_method: 计算叶子节点值的方法,default=Gradient- Newton
- Gradient
thread_count: 训练期间的进程数,default=-1,进程数与部件的核心数相同random_seed: 随机数种子,default=0use_best_model: 如果有设置eval_set设置了验证集的话可以设为True,否则为Falseverbose: 是否显示详细信息,default=1logging_level: 打印的日志级别,default=Nonemetric_period: 计算优化评估值的频率,default=1ctr_leaf_count_limit: 类别型特征最大叶子数,default=Nonestore_all_simple_ctr: 是否忽略类别型特征,default=Falsemax_ctr_complexity: 最大特征组合数,default=4has_time: 是否采用输入数据的顺序,default=Falseallow_const_label: 使用它为所有对象用具有相同标签值的数据集训练模型,default=Noneclasses_count: 多分类当中类别数目上限,defalut=Noneclass_weights: 类别权重,default=Noneone_hot_max_size: one-hot编码最大规模,默认值根据数据和训练环境的不同而不同random_strength: 树结构确定以后为分裂点进行打分的时候的随机强度,default=1name: 在可视化工具当中需要显示的实验名字ignored_features: 在训练当中需要排除的特征名称或者索引,default=Nonetrain_dir: 训练过程当中文件保存的目录custom_loss: 用户自定义的损失函数custom_metric: 自定义训练过程当中输出的评估指标,default=Noneeval_metric: 过拟合检测或者最优模型选择的评估指标bagging_temperature: 贝叶斯bootstrap强度设置,default=1save_snapshot: 训练中断情况下保存快照文件snapshot_file: 训练过程信息保存的文件名字snapshot_interval: 快照保存间隔时间,单位秒fold_len_multiplier: 改变fold长度的系数,default=2used_ram_limit: 类别型特征使用内存限制,default=Nonegpu_ram_part: GPU内存使用率,default=0.95allow_writing_files: 训练过程当中允许写入分析和快照文件,default=Truefinal_ctr_computation_mode: Final CTR计算模式approx_on_full_history: 计算近似值的原则,default=Falseboosting_type: 提升模式- Ordered
- Plain
simple_ctr: 单一类别型特征的量化设置- CtrType
- TargetBorderCount
- TargetBorderType
- CtrBorderCount
- CtrBorderType
- Prior
combinations_ctr: 组合类别型特征的量化设置- CtrType
- TargetBorderCount
- TargetBorderType
- CtrBorderCount
- CtrBorderType
- Prior
per_feature_ctr: 以上几个参数的设置具体可以细看下面的文档task_type: 任务类型,CPU或者GPU,default=CPUdevice_config: =Nonedevices: 用来训练的GPU设备号,default=NULLbootstrap_type: 自采样类型,default=Bayesian- Bayesian
- Bernoulli
- MVS
- Poisson
- No
subsample: bagging的采样率,default=0.66sampling_unit: 采样模式,default=Object- Object
- Group
dev_score_calc_obj_block_size: =None,max_depth: 树的最大深度n_estimators: 迭代次数num_boost_round: 迭代轮数num_trees: 树的数目colsample_bylevel: 按层抽样比例,default=Nonerandom_state: 随机数状态reg_lambda: 损失函数范数,default=3.0objective: =同损失函数eta: 学习率max_bin: =同border_coucntscale_pos_weight: 二分类任务当中1类的权重,default=1.0gpu_cat_features_storage: GPU训练时类别型特征的存储方式,default=GpuRam- CpuPinnedMemory
- GpuRam
data_partition: 分布式训练时数据划分方法- 特征并行
- 样本并行
metadata: =Noneearly_stopping_rounds: 早停轮次,default=Falsecat_features: =指定类别型特征的名称或者索引grow_policy: 树的生长策略min_data_in_leaf: 叶子节点最小样本数,default=1min_child_samples: 叶子节点最小样本数,default=1max_leaves: 最大叶子数,default=31num_leaves: 叶子数score_function: 建树过程当中的打分函数leaf_estimation_backtracking: 梯度下降时回溯类型ctr_history_unit: =Nonemonotone_constraints: =None
如果有遗漏,具体可以参阅CatBoost python-reference_parameters-list
区分具体的机器学习任务有:
CatBoostClassifier
1 | class CatBoostClassifier(iterations=None, |
CatBoostRegressor
1 | class CatBoostRegressor(iterations=None, |
应用场景
作为GBDT框架内的算法,GBDT、XGBoost、LightGBM能够应用的场景CatBoost也都适用,并且在处理类别型特征具备独有的优势,比如广告推荐领域。
优缺点
优点
- 能够处理类别特征
- 能够有效防止过拟合
- 模型训练精度高
- 调参时间相对较多
缺点
- 对于类别特征的处理需要大量的内存和时间
- 不同随机数的设定对于模型预测结果有一定的影响