一种基于行为序列的用户投保意愿预测方法
背景概述
用户投保意愿的预测,本质上是一个二分类建模的问题。具体地,首先对用户进行用户画像,并根据用户的静态属性、动态行为等对数据进行预处理和特征工程,接着,综合运用统计学和保险业务领域知识对数据进行特征提炼,并在业务上积累获取一定数量的正、负样本后,利用逻辑回归、决策树以及梯度提升树等集成学习算法,甚至是深度学习算法来建立模型,得到预测模型和相应的模型参数。最后根据使用场景的不同对模型进行离线或者在线部署,来预测带相关入模特征的新用户,得到预测结果。基于模型预测得到的结果会被推送给保险业务人员,为保险业务的精准营销提供基础。
在相关技术中,处理特征工程时需要对用户的行为进行分类,然后根据业务知识对不同类型的行为进行分时段的统计,从次数、频率、变化率等方面对用户进行多方面的描述以获取用户特征数据。因此,现有模型的预测效果严重依赖于特征工程所产生的特征质量,而特征工程又取决于数据质量和业务领域知识,尤其是业务领域知识,内容复杂且专业,对一些非本领域的工程师来说很难做到精确全面;此外,针对数据质量方面,需要对数据进行一系列的去噪等预处理,耗时比较大。
因此,基于传统的特征工程按步就班地进行投保意愿预测存在着预测精度受制于领域知识,同时也存在着效率低下的问题。笔者借助Embedding技术直接对用户行为序列进行编码,然后利用CNN以及Transformer等深度学习网络直接从用户行为到投保意愿的端到端预测模型,试图解决上诉问题,模型上线后在实际的投放使用当中也取得了不错的效果。
数据类型
本模型所使用的源数据是一种用户行为的序列数据,从记录用户行为的事件日志数据抽取而来,详细记录了用户在公司各个客户当中的所发生的不同类型的事件以及事件发生的时间。目前,我们对不同的客户进行命名,然后对于支持的行为事件进行分类,比如常见的登录、注册等,最后我们将不同客户和可能的行为事件类型进行排列组合,并将这个组合作为后续embedding操作时候的最小单元,相应的这个组合的全集就是embedding所需要依赖的词典。这样讲可能比较拗口,咱们举一个例子。
比如一共有两个客户,分别命名为customer_a和customer_b,有两个支持的行为,分别为login和register,那么在本模型在对序列进行处理的时候中将customer_a=>login这一组合当作一个词(Word),然后所有客户和所有行为进行分别枚举组合的全集就是后面在对每个词进行One-hot编码的时候的词典(Dictionary),在本例中,词典为['customer_a=>login','customer_a=>register','customer_b=>login','customer_b=>register']。
除了行为事件本身,事件发生的时间也是非常重要的信息,在传统序列模型用于NLP领域时往往只关注词的先后顺序和上下文关系,并没有时间的概念,本模型也将事件发生时间距离当前的间隔天数也作为一个单独的序列。因为这个序列已经是数值型,在embedding之前无需One-hot编码。
网络结构
前面以及提到,用户的行为序列具备天然顺序的特点,如果将一个用户的每一次行为当作一个词,那么可以将他的一段时间内的完整行为序列当作一句话,天然适合采用NLP领域的算法进行建模。
正是基于这样的考虑,本模型在构建网络结构的时候除了考虑CNN,还考虑了自Google发布Attention Is All You Need论文以来在NLP领域大放异彩的Transformer,分别利用的CNN来捕捉局部行为与用户投保意愿之间的关系,利用Transformer网络编码层中的Attention机制来捕捉全局或长程行为与用户投保意愿之间的关系,最后再用相应的Sigmoid函数来预测用户的投保意愿。整个模型的网络结构图如下:
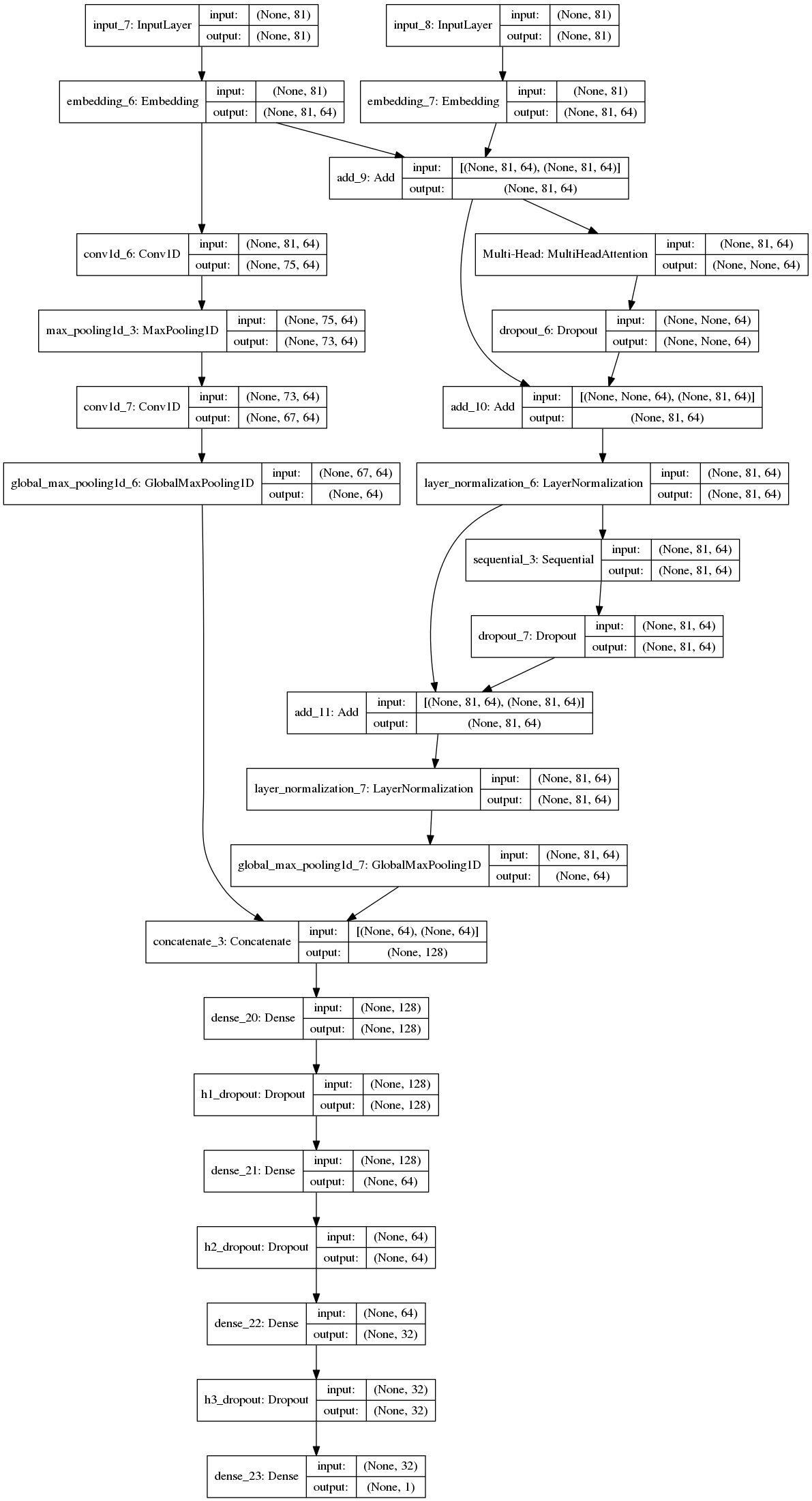
下面对着这张图对整个网络结构做一个简单的介绍。
从上往下,大致的走向是两路输入分别经过Embedding后保留其中一路──行为事件序列──去过CNN模块,以抽取局部行为特征,与Transformer原论文不同的是本模型并没有采用Position Embedding,而是直接使用事件发生时间的距今时长(单位天)的Embedding来代替,将两个向量进行Add处理以后进入类似于Transformer网络encoder层的带Attention机制的处理模块,来捕捉全局或者长程行为的特征。值得一提的时候,这里对原论文中Position Embedding的替换,不但可以表征事件发生的先后关系,也能表征事件发生时间的间隔关系。后续的训练结果也表明这样替换能够小幅提高模型结果。
经过CNN和Transformer两个子模块处理后的向量在各自池化以后拼接到一起后再喂给DNN和Dropout相间的网络,其中DNN的输出维度不但减小,最后变为1维(Sigmoid函数),对应所需要预测的用户投保意愿。
小结
本模型综合运用现有、成熟的网络结构,并针对数据情况和业务场景进行了适当的改进,如果理解了业务和数据,那么理解模型就更为容易。
目前,本模型已经部署并在相关营销业务场景上面试用大半年,取得了一定的效果,相应的专利也在审查当中。