椭圆曲线密码学简介(四):破解安全性及与RSA之间的比较
本文主要翻译自这篇文章。
这篇文章是椭圆曲线密码学简介这个系列的第四篇也是最后一篇。
在上一篇文章当中,我们了解了两种算法ECDH和ECDSA,并且也知道椭圆曲线离散对数问题是如何在安全性方面发挥重要作用的。不过,你如果留心的话,对于离散对数问题的复杂度我们还没有严格意义上的数学证明,只是主观上面认为它是“hard”,但具体是到什么程度还不知道,本文的前半部分会给你一个基于当前技术求解离散对数问题有多“hard”的一个大致认识。
第二部分,我们试着回答这个问题:在RSA等其它基于幂模运算的加密系统工作得好好的时候为什么我们还需要椭圆曲线密码系统。
离散对数问题破解(Breaking the discrete logarithm problem)
接下来我们会看到两个当前最有效的椭圆曲线离散对数求解算法:baby-step,giant-step算法和Pollard's rho算法。
在开始之前,先让我们来回顾一下什么是离散对数问题:给定两个点和 ,寻找整数满足,其中这些点都属于基点为阶为的椭圆曲线子群。
Baby-step giant-step
在进入具体的算法之前,我们快速过一下:对于任意一个正整数,我们总可以将它写成这样的形式:,其中是任意整数。举个例子,对于10我们可以这样写10 = 2·3 + 4。
脑子里面有了这根弦以后,我们可以离散对数问题进行重写:
baby-step giant-step算法是一个在中间会合的算法。比起逐个计算每一个来找到满足方程要求的,对于我们可以计算得更少,对于也可以计算得更少,直到我们找到一个满足条件的。算法的具体工作步骤如下:
- 计算
- 对于中的每一个,计算并将结果保存在一张哈希表当中
- 对于中的每一个:
- 计算
- 计算
- 检查哈希表并寻找是否存在一个点满足
- 如果存在这样的表,那么我们就找到了这样的一个整数
正如你所看到的,我们计算时的系数用很小的步长,但在第二部分当中,我们计算使用很大的步长,这两部分分别就是算法“baby”部分和“giant”部分。具体它可以如下图所示:
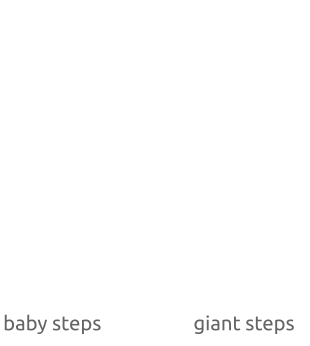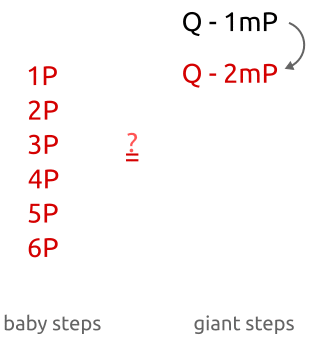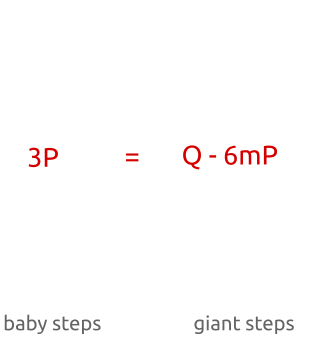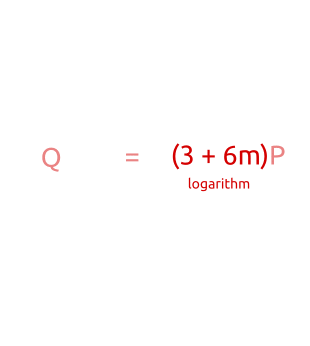
为了理解这个算法为何有效,先暂时不考虑点被缓存起来了,我们直接来看方程,看以下步骤:
- 当时,我们检查是否等于,其中是 之间的一个整数。这样子,我们就可以将与所有从到 之间的点进行比较
- 当时,我们检查是否等于,我们就可以将与所有从到 之间的点进行比较
- 当时,我们可以将与所有从到 之间的点进行比较
- …
- 当时,我们可以将与所有从到 之间的点进行比较
总结一下,我们最多在步的加法和乘法当中检查完所有从到 的点,精确的说baby steps是步,giant steps最多步。
如果将哈希查表的时间复杂度考虑为,不难发现整个算法的时间和空间复杂度均为,如果你考虑了字节的长度,则是。这依然是指数级别的时间复杂度,不过比起暴力破解还是要好不少。
Baby-step giant-step in practice
在实践当中我们可以看看到底意味着什么。我们先找一个标准曲线:prime192v1。这条曲线的阶为
现在想象一下在一个哈希表当中存储个点,假设每个点需要32字节的空间,那么我们的哈希表需要大约2.5·字节的内存空间。目前整个世界的存储能力比起这个需求都相差甚远,即便每一个点只需要1个字节的存储空间,我依然离将它们全部存下来相去甚远。
更加令人绝望的是prime192v1是阶数最低的曲线。另外一个来自NIST的标准曲线的阶数高达6.9·,其时间和空间的复杂度更加不可想象。
Playing with baby-step giant-step
原作者也写了一段python代码实现了baby-step giant-step算法。显然,它只能在一些阶数比较小的曲线上面工作,不要试着去采用secp521r1,否则会出现内存错误。
这段代码可以产出下面这样的一个输出:
Curve: y^2 = (x^3 + 1x - 1) mod 10177
Curve order: 10331
p = (0x1, 0x1)
q = (0x1a28, 0x8fb)
325 * p = q
log(p, q) = 325
Took 105 steps
Pollard’s
Pollard's rho是计算离散对数问题的另外一个算法。和baby-step giant-step算法一样,它的时间复杂度也是,但是它的空间复杂度仅仅为$O(1)。如果baby-step giant-step无法解决离散对数问题是因为巨大的存储空间需求,那么Pollard's rho是否可以呢?让我们拭目以待。
首先,再次强调一下离散对数问题的形式:给定和 ,寻找满足 。在Pollard's rho算法当中,我们求解一个略微不同的问题:给定和 ,寻找整数满足 。
当上面这四个整数找到以后,我们可以结合方程解除:
将消除就可以得到。不过在这样做之前,我们必须记住我们的子群是以阶为的循环子群,因此在点乘法当中使用的系数是要进行模处理的,具体的求解过程如下:
Pollard's rho算法的操作原则非常简单:我们产生一系列的伪随机点,其中。这个序列可以通过一个伪随机函数产生:
伪随机函数以最新的点作为序列的输入,然后以系数和 作为输出。由此,我们可以计算,随后,我们可以再次以作为输入得到新的系数,这样不断重复。
至于伪随机函数内部是如何工作的并不重要,当然,确定的函数比起其它不确定的可以更快地获得结果。我们真正在乎的是基于前一个点来确定下一个点,这样所有的系数 和对我们而言变成已知。
用这样的函数,我们迟早会在我们的序列当中看到一个循环,从表达式上面看就是得到一个点,如下图所示:

我们必须看到循环的原因非常简单:点的数目是有限的,因此我们迟早会重复。一旦我们看到循环在哪里开始,我们可以用这个上面的方程来求解离散对数问题。
接下来问题变成我们如何高效的检测到这个循环呢?
Tortoise and Hare(快慢指针法)
为了检测循环,我们有一个高效的方法:tortoise and hare算法,也被叫作Floyd's cycle-finding算法。下面的图片展示了torise and hare算法的操作原则,也是Pollard's rho算法的核心。
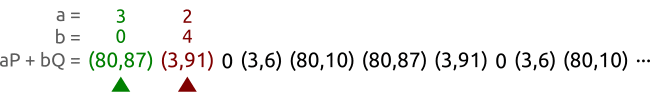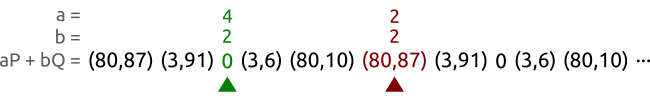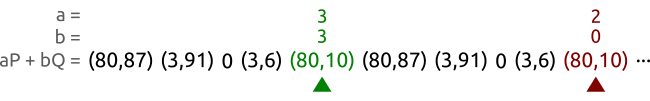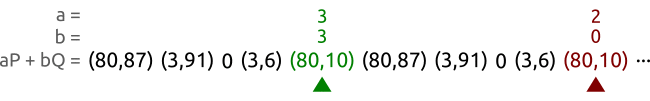
我们基于曲线和点 以及点.这些点属于一个阶为5的循环子群。我们以不同的速度在一个序列对中进行工作直到找到两个不同的整数对和 产生同一个点。在这个例子当中,我们找到整数对和 满足这个要求,然后我们可以计算该对数问题得到,而事实上我们确实有。
我们让tortoise和hare从序列的左边走到序列的右边,绿色的是走得慢的tortoise,一步一步地走,红色的hare每次跳过一个点得走,本质上是快慢指针法来寻找循环开始的地方。
一段时间以后,tortoise和hare会找到相同的点,但是系数对却不相同。或者用方程来表达,tortoise找到的对是,hare找到的对是,且满足。
非常容易看出这个算法只需要固定大小的内存空间。但是计算时间依然开销很大,可以从概率的角度来证明时间复杂度为。严格的证明是基于birthday paradox,指的是两个人生日相同的概率,这和我们所考虑的两个不同的整数对得到相同的点的概率类似。
译者注,根据文章最后的留言讨论,实际上, 原作者关于 Pollard’s ρ 算法的部分讲解是不够准确的。根据作者的前面的说法系数(a,b)总由它前面点决定, 这也就是说, 相同点一定生成相同的系数, 而 GIF 动图中的点(3,6)第一次生成了 a=3,b=3 但第二次生成了 a=2, b=0. 这与前面的说法是矛盾的,对照作者提供的python代码,下一个点的系数并非由前一个点生成, 而是由前一个点和前一个点的系数共同决定。而下一个点又能由前一个点决定, 系数和点的不同循环周期创造了找到问题的解的可能。
Playing with Pollard’s
原作者有一段使用Pollard's rho算法的python代码,这不是原始Pollard's rho算法的实现,只是一个小小的变种,作者使用了更高效的产生伪随机序列的方法。代码里面包含了一些有用的注释,如果你对算法的详细细节有兴趣,最好读一读。
和baby-step giant-step算法一样,也仅仅在一些小的椭圆曲线上面有效工作,并产生类似的输出。
Pollard’s in practice
由于空间需求无法满足,baby-step giant-step在实践中是无法使用的。而Pollard's rho只需要很少的空间,那么他的实用性如何呢?
Certicon在1998年发起了一个在位数从109到359的椭圆曲线上面计算离散对数问题的挑战,最终只有109位的曲线被成功破解,且最好的成功尝试是在2004年提交的,Wikipedia上面的记录如下:
The prize was awarded on 8 April 2004 to a group of about 2600 people represented by Chris Monico. They also used a version of a parallelized Pollard rho method, taking 17 months of calendar time.
正如我们之前所说,prime192v1是一个最小的椭圆曲线。我们也知道Pollard's rho的时间复杂度是。如果我们使用与Chris Monico相同的技术(同样的算法,同样的硬件,数量相同的机器),那么在prime192v1上面计算离散对数问题需要化多长时间呢?
这个数字可以清楚的说明使用这样的技术来破解离散对数问题是多么的困难。
Pollard’s vs Baby-step giant-step
将baby-step giant-step代码和Pollard’s rho代码和brute-force代码放到一起组成第四段代码来比较他们之间的性能。
运行第四段代码可以对比所有的算法在一个阶数较小的曲线上面求解一个离散对数问题所需要的时间对比:
Curve order: 10331
Using bruteforce
Computing all logarithms: 100.00% done
Took 1m 12s (5182 steps on average)
Using babygiantstep
Computing all logarithms: 100.00% done
Took 0m 3s (152 steps on average)
Using pollardsrho
Computing all logarithms: 100.00% done
Took 0m 8s (139 steps on average)
正如我们所期望的,暴力法(brute-force)比起另外两种算法要慢很多。Baby-step giant-step是最快的,Pollard's rho要比它慢一倍,虽然它所消耗的内存更少步数也更少。
再来看运算步数,暴力法平均需要5182步,这个数字非常接近曲线阶数的一半。Baby-step giant-step和Pollard's rho平均分别需要152和139步,两者都非常接近阶数的平方根:。
Final consideration
在介绍这些算法的时候,我已经给出了很多的数字。阅读的时候需要给他们足够的重视:算法可以有很多种方式来进行优化。硬件可以提升,可以构建专用硬件设备。
目前看起来不可行的方法,并不意味着后续不能提升。更不是说已经没有其它更好的方法存在。
Shor’s algorithm
如果当前的技术不合适,那以后的呢?确实,事情的发展让人有些担忧:存在一种量子算法可以在多项式的时间复杂度内解决离散对数问题:Shor’s algoritm的时间复杂度是,空间复杂度是。
量子计算机目前还没有成熟到足以运行Shor’s这样的算法,但是抗量子的加密算法现在看来将会更加有研究价值,今天我们用于加密的东西在明天可能变得不再安全。
ECC and RSA
现在让我们忘记量子计算,把它当作一个严重问题的日子和远着呢!接下来要回答的问题是:既然RSA已经可以很好的工作,为什么还要大费周章地去捣鼓椭圆曲线呢?
NIST给出了一个简洁的答案,提供了一个取得相同等级的安全性能时两者密钥所需字节大小的对比表格:
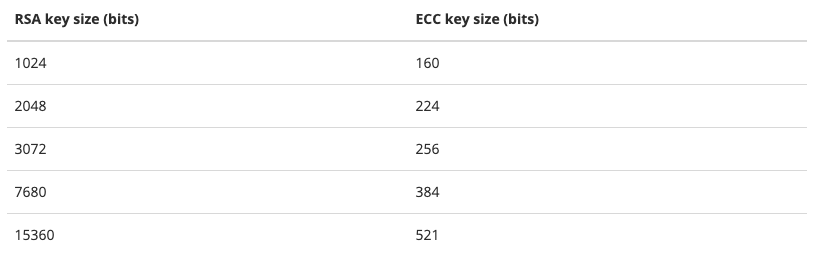
需要注意的是,在RSA的密钥长度和ECC的密钥长度之间并没有线性关系,换言之,如果我们翻倍RSA的密钥长度,并不意味着必须对ECC的密钥长度进行翻倍。这个表格不仅告诉我们ECC使用更少的内存,而且密钥的产生和签名验证都更快。
那么这是什么原因呢?在计算离散对数问题时我们比较快的算法是前面介绍过的Baby-step giant-step算法和Pollard's rho算法,而在RSA的计算当中,我们有着更快、更高效的算法。特别是general number field sieve:一个整数因子分解算法可以用于计算离散对数,该算法是目前最快的因子分解算法。
所有这些都可以应用与其它基于幂模运算的加密系统,包括DSA,D-H和EIGamal等等。
Hidden threats of NSA
接下来是较难的一部分。到目前我们一直在讨论算法和数学。下面让我们把人考虑进去,这将会让问题变得更加复杂。
首先让我们放出问题,问题是:NIST曲线的随机数种子是哪里来的?答案是令人失望的:我们并不知道。这些种子并没有经过大家一致讨论而被认为是正当的。
是不是有这种可能,NIST发现了大量的弱椭圆曲线,然后尝试了大量可能的种子找到了一个有漏洞的曲线?这个问题我无法回答,但是却非常重要且关乎法律。我们知道,NIST确实成功标准化了至少一个有漏洞的随机数生成器。或许他们也能够标准化出一系列的含有漏洞的弱椭圆曲线。对于问题的答案,我们依然无法知晓。
尤其重要的是,需要特别理解的是“可验证的随机”和“安全”并不是等价的。不论你的离散对数问题有多难,你的密钥有多长,如果算法本身被破解了,皮之不存,毛将焉附,那么我们也是束手无策的。
基于这一点的考虑,RSA胜出。它并不需要特别的可能可以作弊的领域参数。在我们不信任任一权威机构以及自己无法构建我们自己的领域参数的时候,RSA以及其它基于幂模运算的加密系统是一个好的替代选择。如果你问:是的,传输安全层(TLS)可以使用NIST的曲线。如果你检查一下google,你可以看到连接就是使用了ECDHE和ECDSA,基于prime256v1的认证证书。
That’s all!
最后,希望大家能够喜欢这一系列的文章。我的目的是能够给大家介绍基本的知识、术语和惯例来理解当前的ECC。如果能够达成我的目标,你现在可以理解现存基于ECC的加密系统并将你的知识延伸到阅读一些其它不那么友好的文档。当撰写这一系列的文章的时候,我本可以跳过一些详细细节,使用一个更简单的术语,但我觉得这样做你将无法理解。我相信我在简单和面面俱到之间做了很好的权衡。
务必注意,仅仅通过阅读本系列文章,你并不能实现安全的ECC加密系统,为了确保安全性,我们需要了解很多细微但重要的细节。记住Smart’s attack和Sony’s mistake──这两个例子应该可以让你知道产生不安全的算法是多么的容易,不安全的算法被人恶意利用也是多么的容易。
那么,后面如果有志于更加深入的探索ECC的世界,应该从哪里开始呢?
首先,我们以及了解了质素域上的Weierstrass椭圆曲线,但是你必须知道还有其它类型的曲线和域,特别是以下几种:
- 二元域上面的
Koblitz曲线:它们是形如(其中是0或1)定义在包含(其中是质数)个元素的有限域上的椭圆曲线。它们可以实现特别高效的点加和标量乘法。标准化的Koblitz曲线有nistk163,nistk283,nistk571(这三条曲线分别定义在 163, 283 和 571 位的域上) - 二元曲线:这类曲线与
Koblitz曲线类似,它们是形如(其中是整数,通常来源于一个随机数种子)。顾名思义,二元曲线被限制在二元域上。标准化的二元曲线有nistb163,nistb283和nistb571。 必须要说明的是, 有越来越多的担忧认为Koblitz曲线和二元曲线可能并没有质数曲线那么安全 Edwards曲线:它们形如(其中是0或1)。它们特别有趣,不仅在于点加法和标量乘法特别快,而且计算点加的公式在任何情况下()都是一样的。该特性充分考虑了旁路攻击的可能性,即当你在测量标量乘法所耗费的时间以后用这个计算所耗费的时间来猜测标量参数的一种攻击方式。Edwards相对较新(2007年出现),目前尚未有Certicom或NIST之类的权威机构对其进行标准化Curve25519和Ed25519是两种分别为ECDH和ECDSA的某种变体特别设计的椭圆曲线。 和Edwards曲线一样, 这两种曲线也很快速并且能够抵御旁路攻击。也和Edwards曲线一样, 这两种曲线也尚未被标准化所以我们不能在流行软件中看到它们的身影(除了OpenSSH, 它从 2014 年起支持了Ed25519密钥对)
如果你对 ECC 的实现细节感兴趣, 那么我建议你阅读 OpenSSL 和 GnuTLS 的源码。
最后,如果你对数学细节感兴趣,而不是算法的安全性和有效性,你必须知道:
- 椭圆曲线是亏格(genus)为 1 的代数变体
- 无限远处的点的概念来源于影射几何(projective geometry) 并可以通过齐次坐标(homogeneous coordinates)来表现 (尽管椭圆曲线并不需要影射几何中的绝大部分特性)
更别忘记研究有限域(finite fields)和场理论(field theory)。
如果对这些主体感兴趣,可以通过上面的这些关键字去了解。
现在这个系列文章就正式结束了,感谢大家的阅读,下次再见!
译者后记
原作者Andrea Corbellini 是一个善于总结和表达且喜欢与人互动的工程师, 通过阅读和翻译他的文章,让我受益非浅。从最基本的曲线方程,结合代数和几何两个维度,从连续域到离散域,循序渐渐,步步深入,慢慢揭开ECC的神秘面纱。看了网上不少这方面的博客,不得不少,从质量和可理解性上,他的系列文章是最高的,而且到目前,我也看到不仅仅是我一个人还在翻译学习他的文章。另外,在文章的最后,他的给出了很多后续扩展阅读的方向,从数学上的,从算法上的,从工程实现上的……等等,继续学习,为了求知而求知,与各位有兴趣的读者共勉!