如何用Go打造区块链(2)—工作证明机制(PoW)
介绍
在如何用Go打造区块链(1)—基础原型当中我们构建了一个简单的但却是区块链数据库的核心的数据结构。同时,我们也实现了向该数据库当中添加链式关系(chain-like relation)区块的方法:每一个区块都链接到它的前一个区块。令人遗憾的是,我们所实现的区块链有一个致命缺陷:添加新的区块太容易,成本也太低。区块和比特币的重要基本特征之一就是添加新的区块是一项非常难的工作。今天我们将处理完善这个缺陷。
工作证明(Proof-of-Work)
区块链的重要设想就是如果你要往里面添加新的区块就要完成一些艰难的工作。而正是这种机制确保了区块链的安全和数据的一致性。同时,给这些艰难的工作适当的奖励(这也是人们挖矿获取比特币的机制)。
这种机制与现实非常类似:一个人必须通过努力工作获得回报以维持生计。在区块链当中,网络上的参与者(矿工)的工作维持网络的正常运行,向区块链中加入新的区块,并因为他们的努力工作而获得回报。他们的工作结果是将一个个区块以安全的方式连成一个完整的区块链,这也维护了整个区块链数据库的稳定性。更有价值的是,谁完成了工作必须进行自我证明。
这一整个的“努力工作并证明”的机制被称为“工作证明”(PoW)。它难在需要大量的计算资源:即便是高性能的计算机,也无法快速完成工作。甚至,为了保证新的区块增加速度维持在每10分钟一个,这个计算工作会越来越繁重。在比特币当中,计算工作的目的是为了给区块找一个匹配的并满足一些特定要求的哈希值。同时这个哈希值也为工作服务。因此,实际的工作就是寻找证明。
最后一点需要注意的,PoW算法必须满足一项要求:虽然计算很困难,但是工作证明的验证要非常容易。因为证明通常会传给网络上的其他参与者进行,不应该消耗他们的太多时间了验证这个证明。
哈希计算(Hashing)
在这一段当中,我们将讨论下哈希值及其计算。如果你对这一概念已经熟悉,可以跳过这部分内容。
哈希计算是取得特定数据对应的哈希值的过程。对于计算出来的哈希值可以作为相应数据的特定代表。哈希函数是针对任意大小的数据产生固定长度的哈希值。哈希的主要特征如下:
- 元数据无法通过哈希恢复。这样,哈希本身并不是加密的过程。
- 特定数据只能有唯一的哈希值,哈希值是独一无二的。
- 即便只是修改输入数据的一个字节,也会导致完全不同的哈希值。
哈希函数被广泛应用于检验数据的一致性。一些软件提供商除了软件包以外会额外发布软件包对应的哈希检验值。在你下载了软件包以后可以将其代入一个哈希函数看生成的哈希值与软件商所提供的是否一致。
在区块链当中,哈希过程被用于确保一个区块的一致性。哈希算法的输入数据包含前一个区块的哈希值,使得修改区块链当中的区块变得不太可能(至少,非常困难),因为修改便意味着你必须计算该区块以及其之后所有区块的哈希值,而这个计算工作量是非常之大的。
Hashcash算法
关于哈希值的计算,比特币采用Hashcash算法,一种最早用于垃圾邮件过滤的带PoW机制的算法。它可以分解为以下的几个步骤:
- 采用一些公开数据(在邮件过滤当中,比如接收者的邮箱地址;在比特币当中,区块头部数据)
- 给它加一个计数器(counter)。计数器从0开始计数
- 将公开数据和计数器组合在一起(Data + counter),并获取组合数据的哈希值
- 检验获得的哈希值是否满足特定的要求
- 如果满足,则计算结束
- 如果不满足,计数器加1并重复步骤3、4
显然,这是一个暴力求解算法:改变计数器计算新的哈希值,检验,递增计数器,再计算一个哈希值,周而复始。这是其计算开销高昂的原因所在。
现在我们从头细看一个哈希值需要满足的具体要求。在Hashcash算法的原始实现当中,对哈希值的要求是“前20位必须为0”。在比特币当中,要求随时间变化有所调整,因为,根据设计,必须每10分钟产生一个区块,不管算力如何增加并有越来越多的矿工加入网络当中。
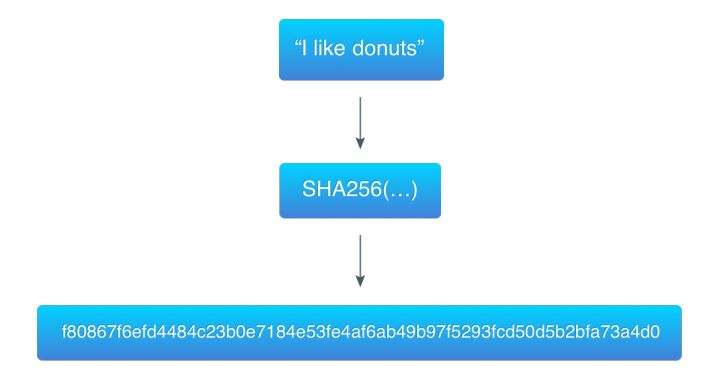
为了证明这个算法,我以前面例子当中的数据(“I like donuts”)为例并产生前面三个字节为0开头的哈希值:
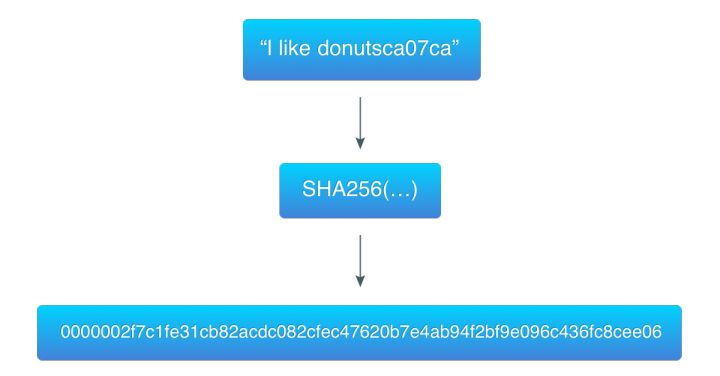
ca07ca是计数器的十六进制数,对应的十进制数为13240266。
实现(Implementation)
好了,理论部门已经清晰明了,让我们开始写代码吧。首先,让我们来设置下挖矿(区块产生)的难度:
1 | const targetBits = 24 |
在比特币当中,“目标位数”(targetBits)是存储在区块头部数据用以指示挖矿难度的指标。目前,我们并不打算实现难度可调的算法。因此,我们可以将难度系数定义为一个全局常量。
24是一个任意的数字,我们的目的是有一个数在内存中所占的存储空间在256位以下。并且这个差异值能够让我们明显感受到挖矿的难度,但不必太大,因为差异值设置的越大,将越难去找一个合适的哈希值。
1 | type ProofOfWork struct { |
上述代码创建了 ProofOfWork 结构体来保存一个区块的指针和一个目标(target)的指针。这里的“target”与我们之前讨论的对哈希值的要求等同。我们之所以用Big整型来定义“target”在于我们将哈希值与目标比较的方式。我们将一个哈希值转换为一个Big整型然后检验其是否小于目标值。
然后在NewProofOfWork函数当中,我们初始化了一个Big整型数据为1并将其赋值给target随后将其左移(二进制的位操作)(256-targetBits)位。256是SHA-256哈希值的总体位数,在本文当中targetBits是24,因此这里总共左移了232位。后面我们也将采用SHA-256算法来产生哈希值。计算后的target的十六进制表示如下:
1 | 0x10000000000000000000000000000000000000000000000000000000000 |
在内存当中占据29个字节空间,下面是将其与我们之前例子中产生的哈希值的直观比较:
1 | 0fac49161af82ed938add1d8725835cc123a1a87b1b196488360e58d4bfb51e3 |
第一个哈希(基于“I like donuts”计算)比target大,不是一个有效的工作证明。第二个哈希(基于“I like donutsca07ca”)比target小,是一个有效的证明。
你可以将target理解成一个范围的上边界:假如一个数(一个哈希值)比这个边界小,有效,反之,则无效。减小边界的数值,会导致更少的有效数字的个数,这样得到一个有效哈希值的难度将加大。
现在,我们来准备需要计算哈希值的数据。
1 | func (pow *ProofOfWork) prepareData(nonce int) []byte { |
上述的 prepareData 方法(因为在prepareData之前有ProofOfWork的结构体声明,这样的一种特殊的函数在Go语言当中叫做method)比较简单明了:我们通过调用bytes包的Join函数将区块信息与targetBits(在比特币当中,难度系数也是属于区块头部数据,这里也把它当做公开数据的一部分)以及nonce(临时值)相合并。nonce变量在这里就是前面Hashcash算法中描述的counter(计数器),它是一个密码学术语。
OK,所有的准备已经就绪,来让我们实现PoW算法的核心部分吧:
1 | func (pow *ProofOfWork) Run() (int, []byte) { |
首先,我们初始化了几个变量:hashInt 是 hash 的整数型代表;nonce 是计数器。接下来我们开始一个循环:循环次数由 maxNonce 来控制,maxNonce等同于math.MaxIn64;这样是为了避免 nonce 的溢出。虽然我们所设置的难度想溢出还是比较困难的,以防万一,最好还是这样设置一下。
在这个循环体内,我们主要做了以下几件事情:
- 准备数据
- 用
SHA-256算法计算该数据的哈希值 - 将哈希值转换成
Big整型数据 - 将转换后的哈希值与
target进行比较
像之前解释的一样简单。现在我们可以删除 Block 结构体的 SetHash 方法然后修改NewBlock 函数:
1 | func NewBlock(data string, prevBlockHash []byte) *Block { |
在此你可以看到 nonce 存储为 Block 的一部分。这是很有必要的,因为 nonce 要用于工作证明的验证。同时 Block 结构体也按照以下代码进行修改:
1 | type Block struct { |
好了,让我运行下程序看看是不是一切工作正常。
1 | Mining the block containing "Genesis Block" |
(^-^)V 现在可以可以看到每一个哈希值以三个字节的0值开头,而且需要花一点时间才能获得这些哈希值。
还剩下一件事情需要完成:让我们来实现工作证明的验证。
1 | func (pow *ProofOfWork) Validate() bool { |
这里也是我们需要将 nonce 保存下来的原因。
让我们再来测试一下一切是否正常:
1 | func main() { |
输出结果:
1 | ... |
结论
我们的区块链离它的实际架构又近了一步:往区块链里面增加区块需要复杂的计算工作,这样挖矿变得可能。然后它依然缺少一些关键的特性:区块链数据库无法持续存在,程序完成后数据就丢失了,也没有钱包、地址、交易记录、共识机制(consensus mechanism)。所有这些特性将会在后面的文章中实现,然后现在,先让我们快乐的挖矿吧!